チーム内外で(テキスト)コミュニケーションを取る時に意識していること
まえがき
この記事は今働いてる会社の社内ドキュメントとして書いた記事の転載ですが、一部切り抜いてツイートしたら割と反響があって社外でも有用そうだということが分かったので全文を転載した記事です。
最近社内コミュニケーションですれ違うことが多いような気がしていたので社内のDocbaseに普段自分が意識してることをまとめたら、slackのrandomでシェアされたりして反響があって良かった。社内に秘匿するものでもないので公開しても良いかもなー。 pic.twitter.com/ahL1BS5L9w
— otani (@canisterism) 2021年9月8日
以下本題をどうぞ。
このメモについて
チーム内でプロダクトの仕様を決定したり相談したりすることはよくあると思いますが、そういった(テキストベースの)コミュニケーションにおいて自分が意識していることを書いてみました。
対象読者
- dev
- ディレクター
- デザイナー
- その他プロダクトの意思決定に関わる人
心がけていること
(自分もいつも出来てるわけではなく、こういうのが理想だなーと思ってることです)
なんでもオープンにやる
- これが一番大事だと思っています。
- slackならできるだけpublicなチャンネルで会話しましょう。
- privateなチャンネル/DMはよほど秘匿性の高いやり取りの必要がある場合のみに留めたい。
- 意思決定の過程には誰でもアクセスできるようにしましょう。
- privateな場で意思決定すると閲覧する権限のない人がついていけなくなったり、またはその人のために別途資料を作ったりするコストが生まれます。
- 不明瞭な意思決定は不信感を生む原因になりかねないので出来るだけ避けたいですね。
- また、publicな場でやり取りしてると知見のある人がコメントをくれたりすることがあって思わぬ進展を生むこともあります。活用していきましょう。
非同期コミュニケーションかつExplicitなコミュニケーション
- 出来るだけ非同期でローコンテキストなコミュニケーションを心がけましょう。
- 非同期とはつまりslackにポストしていつでも相手のタイミングで返信できるようにすることです。
@otani ちょっと今いい? https:/zoom.com/zzzxxxyyyは便利ですが、やっぱりクローズドなコミュニケーションになって情報の非対称性を生むのでデメリットを理解して使うのが望ましいです。- 必ずzoomなどで対面の会話をした時は終わった後に話したこと・決まったこと・その理由をあわせて残すことで他の人にも何が起こったか分かるようにしましょう。
話したい内容は一番先に短く書く
- 「相談です!」「共有です!」など先に書けると読む人の負担が減って嬉しいです。
- 要するに相手にやってほしいアクションが分かるように書きましょう。
- [FYI]などを頭につけておけるとパッと見て共有であることが分かるので使いこなせると嬉しいですね。
決まってないことと決まってることをはっきり書く
- 仕様を決定するようなMTGによくあるのですが、決まってる部分と決まってない部分があやふやになっていて、資料を見た人がどうすれば良いのかわかりにくくなっていることがあります。
- 最悪言いたいことをバァーッと並べて、最後に
#決まってないこと・決めたいことみたいなセクションを並べてそこに要素を羅列するとかでも良いと思います。
アジェンダは先に作って配ろう
- 会議をオーガナイズする人は必ず先にアジェンダを作りましょう。
- 個人的にはアジェンダには結論まで含めておくべきだと思っています。
- 例えば仕様を決定するMTGなら「対象のスコープ」「結論とその理由」「前提・制約」「あり得た選択肢」「懸念事項」などを並べておけると良いですね。
- 会議はそれに話したこと・議論したことを追記していく形で進めましょう。
- 逆に参加する側の人は事前に配られたものは読んでから参加するべきでしょう。
会議は決定・合意の場である
- 上とほぼ被る&話す内容にもよるのですが、会議はなるべく意思決定の合意の場であるべきだと考えています。
- 会議中に議論をするのがダメだとは思ってないですが、下読みした資料を元にして言いたいことがある人はコメントを、なければ事前に決定した結論でGOで済むのが理想的だと思っています。
議事録は必ず共同編集可能なソフトウェアで
ネクストアクションのない会議はやめよう
- 会議はそこで意思決定を行うことで次に何をすればいいかが決まる場所だと思っています。
- なんとなく話して終わったMTGは何も決まってないし何も前に進まないのでそれは雑談です。
- 必ずネクストアクションには誰がボールを持っているか、期限はいつまでかを書きましょう。
- 「〇〇が今日まででにやってると思ってた」は悲しみしか生まないので必ずやりましょう...必ず...
- なんだかコンサル向けの自己啓発本みたいですが、1回でも欠かしたら意味がなくなるので僕は必ずやるようにしています
すべてのドキュメントはトラッキング可能である
- slackのスレッドで議論して仕様が決まることはよくあると思いますが、他の場所でその意思決定について言及する時はどこで決まったのか、議論の内容が分かるように最低限スレッドのリンクを貼り付けるようにしましょう。
- その他、決定事項や文脈については雑にリンクを貼り付けてあげると良いですね。
- 議事録は後から振り返って参照するものなので、決まった時の経緯が分かるようにしましょう。
フロー型とストック型を意識して残す
- 上で言及したことと重なりますが、slackのログは流れてしまうものなのでできれば決定事項はストック型のドキュメントに残すのが望ましいです。
- 例えばpaperとかesaとか、後から振り返るのに適しているツールとslackのようなフロー型の逐次コミュニケーションに適したツールがあるので意識して残せるとよいですね。
- フロートストックについてはこちら
見出しやスタイルの概念を理解して議事録を作る
- Dropbox paperなどのドキュメントツールにはほぼ必ず見出しなどの文章構造を定義する機能が存在します。(
#を入力すると文字が大きくなったりするアレです) - ↓はhtmlの文書構造の画像ですが、議事録などのドキュメントについても同じようなルールが適用できます。
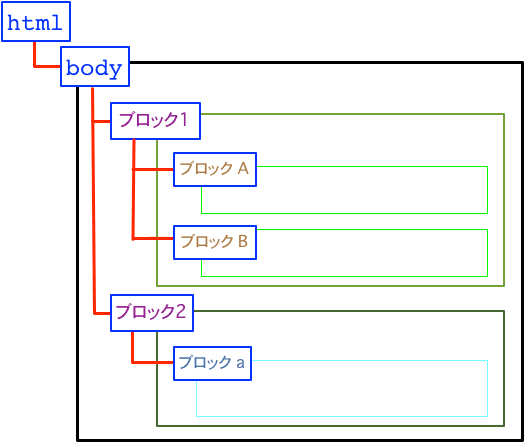
引用: HTMLの文書構造 | 明治大学
- この記事についても文書構造が意識されていて、一番大きい見出しに
# 心がけていること(htmlでいう<h1>)があり、その中に## 見出しやスタイルの概念を理解して議事録を作る(<h2>)のような中見出しが入れ子になって表現されています。 - たまにDropbox paperで全部太字と箇条書きで構成されているのを見かけますが、構造をわかりやすくするために見出しだけでも意識してみるときっと分かりやすくなるはず。
まとめ
- リモートが前提になるとコミュニケーションがテキストベースになるのでこの辺のtipsが役に立ってちょっとでも生産性が上がると良いなーと思います。
GraphQLのいろいろな読み物を読んだ時のメモ
Introduction to GraphQL
- graphqlの仕様をまずはちゃんと読みましょう
- ざっと流し読んで知らないところだけメモる感じで
- fragment辺りの理解が怪しい
Query
{ human(id: "1000") { name height(unit: FOOT) } }
- このクエリ書けるのもしかして俺知らなかった?
- typeのfieldになんか渡すやつ出来るのか
- ルートのtypeは知ってたけど
{
leftComparison: hero(episode: EMPIRE) {
...comparisonFields
}
rightComparison: hero(episode: JEDI) {
...comparisonFields
}
}
fragment comparisonFields on Character {
name
appearsIn
friends {
name
}
}
- aliasもここに出てくるのか
- ほんでaliasすると同じ項目をまとめたいからfragmentが便利ですと。よく出来たドキュメントだ。
- operationNameの有用性について
but its use is encouraged because it is very helpful for debugging and server-side logging. When something goes wrong (you see errors either in your network logs, or in the logs of your GraphQL server) it is easier to identify a query in your codebase by name instead of trying to decipher the contents.
Variables
- variableは動的なクエリストリングの書き換えよりも楽ちんなのでメリットが有るよねという話。言われてみればそうか...
Directives
- directiveも動的なクエリのための機構で、fragmentやfieldに対して付与することが出来る。
Mutation
Inline Fragment
query HeroForEpisode($ep: Episode!) { hero(episode: $ep) { name ... on Droid { primaryFunction } ... on Human { height } } }
Schemas and Types - GraphQL
公式ドキュメントの次の章。
- graphql-rubyでのinterfaceの書き方 https://graphql-ruby.org/type_definitions/interfaces
- 同じようなことをしたいけどそれぞれ違う...要はクラスの継承とだいたい同じでいいと思うんだけど微妙に使い所がわからない
GraphQL Best Practices - GraphQL
公式ガイド、これより前のセクションはだいたい知ってたのでこっち読んだ方が有用そうだったので読んでいく
- 認証とかネットワークとかは手に負えないからGraphqlのドキュメントに載ってないのではなくて、単純にGraphQLそのものというよりはプラクティスの類になるから、だそう
- あくまでプラクティスなので、ケースによっては意図的に無視したりしてもOK
- HTTP
- RESTとは違ってエンドポイントは1つ。複数持ってもいいけどしんどいのでおすすめしません
- JSON
- Versioning
- GraphQLのバージョニングは止められてないけどいろんなツールがあるから避けることをおすすめするよ
- 破壊的な変更が起こるとバージョニングが必要になる。GraphQLは要求されたものしか返さないので破壊的な変更を起こさずに新しい型を追加していくだけで良い。やったね!
- いやそう言っても色々あるでしょうに....
- Nullability
- 多くのシステムでnullは明示的に宣言する必要があるけど、GraphQLはデフォルトがnullだよ
- なぜならGraphQLの背後にはDBや非同期処理などが存在するため、外部要因でデータが不完全になるケースが多く存在するから、という思想に基づいているよ
- GraphQLのサーバーを作る時はあらゆる問題が起こり得ることを想定すると同時に失敗したフィールドに対してはnullが適切であることを覚えておくといいよ
- Pagenation
- Connectionとかね
- Server-side Batching & Caching
- common problemなのでDataLoaderとかで解決できるよ
Thinking in Graphs
考え方みたいなのいっぱい載ってる章。
Working with Legacy Data
- DBのスキーマに負債が溜まってたりような状況の時はそのままGraphQLのスキーマに反映させずにクライアント側に使ってほしい形で書くのが良い。
Build your GraphQL schema to express "how" rather than "what". Then you can improve your implementation details without breaking the interface with older clients.
- ここだけ言ってることが分からん
Serving over HTTP
HTTPとGraphQLの付き合い方について
Web Request Pipeline
殆どのウェブアプリのフレームワークはpipeline model(リクエストはたくさんのmiddlewareを通り抜けて処理されることを期待するモデルのこと)だけど、GraphQLは全ての認証middlewareの後ろに存在しているべき。そうすることで他のHTTPエンドポイントとセッションを共有できる。
Authorization
- 認可はビジネスロジックのレイヤに押し込めるべし。
var postType = new GraphQLObjectType({
name: ‘Post’,
fields: {
body: {
type: GraphQLString,
resolve: (post, args, context, { rootValue }) => {
// return the post body only if the user is the post's author
if (context.user && (context.user.id === post.authorId)) {
return post.body;
}
return null;
}
}
}
});
- こういう型を作ると型の数だけ認可ロジックを作らないといけないので当然漏れる。
- (やってるなぁ........)
- ↓のが望ましい。
//Authorization logic lives inside postRepository
var postRepository = require('postRepository');
var postType = new GraphQLObjectType({
name: ‘Post’,
fields: {
body: {
type: GraphQLString,
resolve: (post, args, context, { rootValue }) => {
return postRepository.getBody(context.user, post);
}
}
}
});
- 改善したいンゴ〜
Pagination
- カーソルベースのページネーションをする時、フォーマットに依存しないようにbase64するのがいいよ
- カーソルを得るためにConnectionとnodeの間にedgeという層を挟むよ
Connection has many edges, edge has one node and cursorになる- このedgeがnodeに関するメタ情報を持ってくれるのでGoodだよ
- さらに、あとどれぐらいページネーションできるかなどのConnection自体の情報を持つためにConnectinoの子にpageInfoを持つよ
- pageInfoはendCursor(レスポンスとして返したリストの最後のカーソル)やhasNextPageなどを返すよ
- おっ公式でfriendsConnectionって名前つけてるな
Global Object Identification
- nodeとIDの話

GraphQL - Authorization - graphql-ruby
- typeやargumentは
authorized?のメソッドをデフォで持ってるのでこれを活用していく。- そもそもここで間違ってるんだよな...
- だいたいこんな感じで認可する。BaseObjectの場合はresolveの後に呼ばれて、falseを返すと結果を返さなくなる。
class Types::Friendship < Types::BaseObject # You can only see the details on a `Friendship` # if you're one of the people involved in it. def self.authorized?(object, context) super && (object.to_friend == context[:viewer] || object.from_friend == context[:viewer]) end end
- Fieldだとこんな感じ。↓ Fieldの
authorized?はresolveの前に呼ばれる。
class Types::BaseField < GraphQL::Field # Pass `field ..., require_admin: true` to reject non-admin users from a given field def initialize(*args, **kwargs, require_admin: false, &block) @require_admin = require_admin super(*args, **kwargs, &block) end def authorized?(obj, args, ctx) # if `require_admin:` was given, then require the current user to be an admin super && (@require_admin ? ctx[:viewer]&.admin? : true) end end
- こういうのをquery_typeに書いてたりするので暇があったらドンドコ移していったほうが良いな
- profile周りどうすればいいかな.........
def wish_lists(user_id:)
return [] unless request_from_owner?(user_id: user_id.to_i) || User.find(user_id)&.profile&.info_public?
UserWishList.where(user_id: user_id)
end
private
def request_from_owner?(user_id:)
context[:current_user]&.id == user_id.to_i
end
GraphQL - Directives - graphql-ruby
directiveで認可の設計できるんだっけ?ということを知りたい
- graphqlのdirectiveには2種類ある。
runtime directives
クライアント側から投げつける
@includeとか@skipとかのdirective。クライアント側でクエリの形を動的に変えたい時に使うやつ。 schema directives スキーマに対してアノテートするディレクティブ。こういうの↓
type User { firstName @deprecated(reason: "Use `name` instead") lastName @deprecated(reason: "Use `name` instead") name }
GraphQL Advent Calendar 2020 - Qiita
なんか見っけた。
GraphQL - Lookahead - graphql-ruby
GraphQL-Rubyのv1.9からlookaheadという、クエリが要求したフィールドをType側で先読みできる機能ができたらしい。
field :files, [Types::File], null: false, extras: [:lookahead] def files(lookahead:) if lookahead.selects?(:full_path) # This is a query like `files { fullPath ... }` else # This query doesn't have `fullPath` end end
- よっぽど重い処理やってないと使わないと思うけど...
初めて Apollo Client を使うことになったらキャッシュについて知るべきこと - WASD TECH BLOG
取得するフィールドに id は必ず含める 更新処理のときは Mutation のレスポンスでオブジェクトのキャッシュを更新する 作成、削除処理のときは refetchQueries などを使い配列のキャッシュを更新する 画面表示のたびに最新のデータを表示したければ fetchPolicy: "cache-and-network" を使う
やっぱapolloとかシュッとしたGraphQL client使ってるとこの辺がスタンダードなんだろうな
Shopify/graphql-design-tutorial - GitHub.com
takadaくんがtimesに貼ってたやつ。
- 中間テーブルがDBに存在しても、ビジネスのドメインで意味がないんだったらスキーマには含めないほうが良い。
特定可能な主要なビジネスオブジェクト(例えば商品やコレクションなど)はNodeインターフェースを実装するべきです。
type Collection implements Node { id: ID! }
Protip: リストのように、Booleanもほとんどいつも非Nullです。 NullableなBooleanを使う場合は、本当に3状態(Null/false/true)を区別する必要があるのかという点と、設計上のより大きな問題を招かないことを確認ましょう。* 手動コレクションの場合にこのフィールドは一体どの値をもつべきでしょうか。 trueとfalseのいずれもミスリーディングのように感じます。 かといってNullableにしたところで3状態を表現するフラグは、自動コレクションの場合に違和感を覚えます。 ルール #6: 密接に関連する複数のフィールドはサブオブジェクトにまとめること。
bodyHtmlは詳細設計なのでdescriptionに変えた上でHtml typeを作るのが良いって言ってるなー- たしかにこのケースだとコンテキスト表すのに型作ったほうが良いか
2つ目は、こちらのほうが大きな問題です、クライアントに実装を要求するという点です。 これは設計哲学における最も重要なポイントのひとつで、つねにサーバーこそが唯一の正しいビジネスロジックの情報源であるべきです。 ほとんどの場合でAPIは複数のクライアントに対して提供されます。 もしそれぞれのクライアントが同じロジックを実装しなければならないとしたら、それはコードの重複を生み、不必要なタスクとエラーが発生させる余地を伴います。 ルール #12: APIはデータだけではなくビジネスロジックを提供すること。複雑な計算はサーバーで為されるべきで、複数のクライアントではない。
- たしかにこのケースだとコンテキスト表すのに型作ったほうが良いか
Mutationについて
- 肥大化するupdateにどう立ち向かうのか?
別々のmutation(addProductやremoveProductなど)に分ける方法。柔軟、効率的で、最もうまくいく。
- 急にポジション取っててウケる
ルール #15: 関連に対する操作は複雑で、ひとつの便利な指針で語ることはできない。 ルール #19: フォーマットが明確であり、クライアント側の検証が複雑な場合には、入力に対して弱い型付け(EmailではなくString)を行うこと。これによりサーバーは一度にすべての検証を実行し、単一のフォーマットでエラーを報告することになり、結果としてクライアントが非常にシンプルになる。
- 分かりみがある
- updateとcreateのIFの話
- 共通にしちゃった
type Mutation { # ... collectionCreate(collection: CollectionInput!) collectionUpdate(collectionId: ID!, collection: CollectionInput!) } input CollectionInput { title: String ruleSet: CollectionRuleSetInput image: ImageInput description: String }
ルール #21: たとえいくつかのフィールドの必須制約を緩和する必要があっても、重複を減らすためにmutationの入力を構造化すること。
- これは意外だなぁ...
各mutationはその他の必要な情報に加えてユーザエラーフィールドを含む"payload"型を定義すべきです。 createのmutationはおそらく以下のようになるでしょう。
type CollectionCreatePayload { userErrors: [UserError!]! collection: Collection } type UserError { message: String! # Path to input field which caused the error. field: [String!] }
data: {"CollectionCreatePayload": {"collection": {...}, userErrors: [...]}を許容するということかー
Designing GraphQL Mutations - apollo blog
後方互換性を保ちながらmutationを設計するためのtips。
Naming
#{動詞}#{名詞}で構成するのが良い- Shopifyは操作対象のデータモデルでアルファベット順に並べたいので
#{名詞}#{動詞}になってるけど、多くのアプリケーションでは操作されるデータとアクション名が対になることが少ない。 - 例えば
sendPasswordResetEmailというmutationは操作対象というよりはRPC(Remote Procedure Call)的な発想なので動詞が先に来て欲しい。- Shopifyよりもこっちのほうが賛成できるな〜〜〜〜
- Shopifyは操作対象のデータモデルでアルファベット順に並べたいので
Specificity
- mutationは汎化させて引数でどうこうするよりも特定のケースごとに作ったほうが良い。
- 例えば
sendEmail(type: PASSWORD_RESET)みたいなmutationは未来の機能拡張によっては引数や返り値が複雑になりうるのでsendPasswordResetEmailとして言い切ってしまったほうが良い。Specific mutations that correspond to semantic user actions are more powerful than general mutations
- とあるのでめっちゃ強い思いを持ってるっぽい
- 例えば
Nesting
input object
- inputは必ず1つのnon-nullかつmutationごとにユニークなinput objectで渡されるべき。要はこういうこと↓
# Good
updatePost(input: { id: 4, newText: "..." }) { ... }
# Not Good
updatePost(id: 4, newText: "...") { ... }
- 小さい違いだけれど、引数の数が多くなった時にGraphQLのmutation stringがかなり違ってくる↓
mutation MyMutation($input: UpdatePostInput!) {
updatePost(input: $input) { ... }
}
# vs.
mutation MyMutation($id: ID!, $newText: String, ...) {
updatePost(id: $id, newText: $newText, ...) { ... }
}
- input objectは可能な限りネストしたほうがいい。
- ネストすると将来的に不必要になったフィールドだけ
deprecatedを付けたりして別のフィールドを置いたり出来る。
- ネストすると将来的に不必要になったフィールドだけ
mutation {
createPerson(input: {
# By nesting we have room at the top level of `input`
# to add fields like `password`, or metadata fields like
# `clientMutationId` for Relay. We could also deprecate
# `person` in the future to use another top level field
# like `partialPerson`.
password: "qwerty"
person: {
id: 4
name: "Budd Deey"
}
}) { ... }
updatePerson(input: {
# The `id` field represents who we want to update.
id: 4
# The `patch` field represents what we want to update.
patch: {
name: "Budd Deey"
}
}) { ... }
}
- そうなのか〜〜〜
- mutation stringの長さが短くなるのはそうなんだけど、結局mutation stringの中でinputから取り出すのは同じだからそこまで短くなるんだっけ?とは思ったけどまぁdeprecatedにしやすいってのは納得した
mutation payload
- mutation payloadに関してもinputと同じことが言えて、ネストするのが望ましい。
mutation {
createPerson(input: { ... }) {
# You could add other fields now to your mutation payload.
# Like `clientMutationId` or `userErrors`.
person {
id
name
}
}
updatePerson(input: { ... }) {
person {
id
name
}
}
}
- 要するにこういう風に書いて、いきなりnameとかidとかのプリミティブな型を置くなという話
- >Preemptively removing design space is not something you want to do when designing a versionless GraphQL API.
- 金言だなぁ
【Flutter】個人開発でゲームレビューアプリをリリースした話
※この記事はZennに投稿した以下記事を転載・一部修正したものです zenn.dev
個人開発でゲームレビューアプリ「clip-games」 をリリースしました
今回の記事はサービスの紹介と技術周りの話をまとめたいと思います。 同じように個人開発している人の参考になったり、モチベーションを上げられたりすると嬉しいです!
リリースしたサービス
ダウンロードはこちら: iOS:

何が出来るの?
- 自分が遊んだゲームの感想・レビューを残すことが出来ます。
- ファミコンからPS5まで、5000本近くのタイトルからあなたが遊んだゲームのレビューを残すことが出来ます。
- 他の人のレビューやそのゲームの評価も見ることが出来ます。
- 遊びたいと思ったゲームや気になっているゲームをクリップすることが出来ます。
- クリップしたゲームはいつでもプロフィールからすぐに確認できるので、ふとゲームがやりたくなったときにすぐに思い出すことが出来ます。
- 書いたレビューはSNSでシェアすることが出来ます。
- レビューはアプリに直接遷移するリンク付きでTwitterなどにシェアすることで、自分がゲームをプレイしたことを友達に伝えることが出来ます。
目指した姿
個人的には「みんなの感想や思い出が集まるプラットフォーム」を目指していますが、1stリリースにあたっては「当たり前のことが当たり前にできるSNS」を目指しています。 また、UIはTwitchのようにゲーマーに愛されるスタイリッシュな画面を目指しました。
アプリ内画面一覧
トップ画面には最新のゲームや最近レビューされたゲーム、人気のゲームなどが並んでいます。 検索は機種別の検索やフリーワード検索で約5000タイトルから探せます。
| トップ画面 | 検索結果画面 |
|---|---|
| |
|
ゲームの詳細画面にはゲーム自体の情報や、付けられたレビューの点数や、最近投稿されたレビューなどが表示されます。
| ゲーム詳細画面 ① | ゲーム詳細画面 ② | レビュー画面 |
|---|---|---|
| |
|
|
プロフィール画面では自分が遊んだ/クリップしたゲームがひと目で分かるようになっています。
| プロフィール画面 | 通知画面 |
|---|---|
| |
|
作ろうと思ったきっかけ・モチベーション
作ろうと思った理由は、ざっくり言うと「なんか作りたい!」と思ったところから始まり、次に「自分が欲しい!」と思ったからです。
なんか作りたい!
webエンジニアの方なら分かると思いますが、技術力の研鑚のためにプライベートで手を動かす人は少なくないでしょう。僕もそうありたいと思っている一人なのですが、「何のためにやるのか?」が自分で分かっていないと手が動かない質でした。
clip-gamesの開発を始めた2020年は業務でFlutterを書き始めた年で、プライベートでも何かしら作りたいな〜と思っていて、技術力を上げるための目的を探している途中でした(また、Flutterと相性の良いFirebaseも合わせて使いたいと思っていました)。
テーマを探す
突然ですが、僕はゲームと映画が好きです。他の人と比べて突出したハマり方をしてる人ではありませんが、なんとなく最近のトレンドは知っていて話題の作品はきっかけがあれば手を出してみようかな、と思っているぐらいの好き度です。 そして、ある時映画のレビューサイトを眺めていて、これに相当するゲームのレビューサービスが無いことに気付きました。^1
自分が昔遊んだゲームの記録を残したり、最近気になっているゲームや教えてもらったおすすめのゲームをメモっておけるサービスがあったら使ってみたいぞ...!?と思い立ち、ゲームのレビューサービスを作ることにしました。
余談
これは余談ですが、他にも作ろうと思ったモチベーションはあって、例えば「自分が作ったと言えるものが欲しかった」などがあります。私が今所属しているチームでは個人開発で作ったプロダクトを持っているメンバーが多く、彼らのように「これは私の作ったサービスで...」といえるものが欲しかったのは大きなモチベーションの1つです。
技術スタック
clip-gamesの技術スタックについて紹介します。
- モバイルアプリ: Flutter
- 状態管理: Riverpod + StateNotifier + Freezed
- バックエンド: Firebase
- 認証: Firebase Authentication
- DB: Firestore
- バックエンドロジック: Cloud Functions
- node.js + typescript
- アプリへのリンク: Dynamic Links
- 検索エンジン: Algolia
モバイルアプリをFlutterで、バックエンドはFirebaseで作っています。
FlutterはGoogle製のモバイルクロスプラットフォームのフレームワークで、1つのコードでiOS/Android両方を動かすことが出来ます。公式のチームやコミュニティによる開発が活発で、最近はiOS/Androidに加えてWebも作れるようになるなどしておりさらなる発展が見込まれます。
FirebaseもGoogle製のmBaaS (mobile Backend as a Service)です。今や説明不要かと思いますが、DBや認証などのバックエンドに関わる部分をまるっとGoogleが面倒を見てくれるサービスです。
Flutter + Firebaseはいいぞ
FlutterはFirebaseと相性が良いというのがもっぱらの触れ込みですが、実際に使ってみた感覚はかなり良かったです。FlutterのFirebase向けのライブラリは公式のFlutterチームによってメンテされており、基本的にはドキュメントを見ればやりたいことが実現できました(まぁ細かいこと言い出すと足りない部分は無くはないですが私は概ね満足しています)。
Flutterのフレームワークとしての完成度もかなり満足度が高いです。最近のWebフロントエンドよろしく宣言的UIを謳っているため、ReactやVueに近いような書き味+フレームワーク側の抽象度の設計のクオリティが高いため、用意されたUIコンポーネント(Widgetと言います)を組み合わせることで自由度の高いUIを作ることが出来ました。1
Algoliaもいいぞ
clip-gamesは検索エンジンにAlgoliaを採用していますが、こちらもすごく体験が良かったので紹介したいと思います。
FirebaseのDBであるFirestoreはNoSQLと呼ばれるスキーマレスDBであり、Like検索がデフォルトで用意されていません。そのため、Firestore単体ではゲームタイトルの検索などが行えません。2 公式のドキュメントにはAlgoliaやElasticSearchなどのサードパーティの検索プロバイダを使えと書いてあります。
公式に従ってAlgoliaを使ったのですが、とりあえずレスポンスがめちゃくちゃ早いのが良かったです。 また、ドキュメントがよく整理されていたり(英語)、中の人達によるプラクティスや解説の記事が豊富で非常に助かりました。
(ただし、clip-gamesは検索の対象であるゲームのドキュメント構造が非常に簡単だったので相性が良かった、という話であることに注意してください。多段にネストさせたjsonなどを格納するのをalgoliaは不得意としているので要件と相談しましょう)
(また、Flutterにはalgoliaの公式のクライアントライブラリが存在しません。非公式のライブラリが存在しますが、この点は注意が必要です)
良かったこと
- 1人でサービス立案からリリースまでやり切る経験を積めた
- 自分で全部判断してサービスの設計や機能追加ができた(純粋に楽しかった)
- Flutter + Firebaseがホンノチョットワカルになった
大変だったこと
Firestoreわからん問題
私はこれまで業務でRDBにしか触れたことがなく、NoSQLがどういうものなのか、保守性や拡張性、セキュリティなどに関する知識やプラクティスを知りませんでした。
ぶっちゃけ最初の何週間か分からなすぎて途方に暮れたのですが、こちらの実践Firestore (技術の泉シリーズ(NextPublishing)) にかなり救われたのでここで紹介します。
https://www.amazon.co.jp/dp/484437852X
NoSQLとしての設計の勘所や、同じFirebaseのサービスであるFirebase AuthenticationやCloud Functionsと組み合わせた時のプラクティスなど、Firestoreをメインに何かを作る時に必要な知識が詰まっています。これがなかったら果たしてclip-gamesは完成したかわからない、ぐらいにお世話になりました。本当にありがとうございます...!
モチベーション持たない問題
clip-gamesのサービス立案〜リリースまでの開発期間はおおよそ7ヶ月です。個人開発なのでずっと1人で開発しています(当たり前ですが)。途中で何回燃え尽きかけたか分かりません。事実中頃の1ヶ月とリリース直前の1ヶ月はほとんど稼働していない期間だったりしました。
もう個人開発あるあるだと言っていいと思いますが、個人開発は孤独なのでモチベーションの維持が非常に難しいです。「これ作る必要あるんだっけ?」という悪魔のささやきや、技術的な困難さにぶち当たってやる気が無くなってしまうこと、自分の出したアウトプットのクオリティが低すぎて嫌になることなど、数えだすとキリがありません。
皆さんいろんな工夫をされていると思いますが、僕が試した中で有効だったものをざっくり上げておきます。
- プロダクトに共感してフィードバックをくれるユーザーを見つける
- 個人的に一番大事だと思います。フィードバックがない開発はつまらない。
- スケジュールをブロックして時間を確保する
- esaに作業ログをつけることで途中で脱線して別の作業を始めてしまうのを防ぐ
- ハードルの低い作業から始めるルーチンを作ることで作業興奮を活かす
- 社内のもくもく部屋slackチャンネルで作業することを宣言する
これからのclip-gamesについて
clip-gamesはまだリリースしたばかりなので、やっとスタートラインに立ったところです。 今のclip-gamesはアプリ内のコンテンツ量(レビュー量)が少ないので、より多くのユーザーに使ってもらい、レビューを残してもらうことを目標にしています。
SNS系のアプリの難しいところですが、そのサービスに投稿されたコンテンツの量がそのままサービスの価値になるため、ユーザーがいないのでコンテンツが少ない→コンテンツが少ないのでサービスの価値が低い→潜在ユーザーが魅力を感じないのでユーザーが増えない...というループを以下に抜け出すかが勝負になると思っています。
まぁコツコツやっていくしか無いのだと思いますが、これからもより多くの思い出や感想が集まるアプリにするため開発は続けていきたいと思います!
この記事を見ているあなたも、良ければ最近遊んだゲームや昔プレイしたゲームの感想をclip-gamesに残してみませんか?
ダウンロードはこちら: iOS:
フィードバック・問い合わせ
アプリに関するフィードバック・問い合わせ・バグ報告はclip-gamesのTwitterアカウントまでお寄せください!
https://twitter.com/clip_games_
お世話になった方や記事など
Flutter / Firebaseの設計やプラクティスを参考にさせていただいた方々
https://mono0926.medium.com/ https://twitter.com/heavenOSK https://medium.com/@riscait https://www.youtube.com/channel/UCmbwk54FJxio-rBN2o6L7zQ https://twitter.com/kabochapo
フィードバックをくれた方々(同僚・運営者ギルドのみなさま)
はてなブログを再開します
otani、ブログ再開するってよ
ブログを再開しようと思います。
モチベーションについて
現職からいわゆるwebエンジニアとして働きはじめて3年経った訳だけど、なんとなく「副業とかやってもいいのかな〜」とぼんやり考えたところで自分がどういう人間でどういう事ができる人間なのかを表すアウトプットがまるで無いことに気付いた。
読書メモやアプリ作ってた時の作業ログはesaにほそぼそと残してるものの人に見せられるようなものではないしね...。
まぁ何個かアプリを作って出したりはしたんだけど、もっと具体的なレベルで実力や興味の範囲を図れるような、他の人にとって読みやすかったり有意なアウトプットがない、という感じだろうか。あと単純に自分が普段やったことに関して考えを整理してアウトプットする場がなくてもにょっていたのもある。きちんとアウトプットしないと思考が浅くなるね。
技術に閉じたプラットフォーム(Qiita, 最近でいうとZenn)で書けばええやんという話かもしれないけど、技術から微妙に離れたライフハック的な話が書けなくなると自分のアウトプット先が複数に分かれてしまうのであまりよろしくないかなと思っている。
という訳で3年近く書くのをサボって更新が死んでいたこのはてなブログが一番ええやろという発想で今に至っている(久しぶりに開いたら最終更新が「Vue.jsでブログを作ります!!」的なタイトルがついた記事が当時のwebエンジニアワナビーっぷりを遺憾なく発揮していて死にたくなった。しかも全体設計編で更新が途絶えていた。せめて最後までやりきってくれ)。
(はてなブログ自体にすごくポジティブかと言われるとそれもまた微妙ではあるんだけど)
何を書くのか
ここ1,2年は公私ともに真面目に手を動かしていろんな失敗と成功を積んだつもりなのでその辺りをちゃんと整理してアウトプットしたいなと思っている。具体的には以下のような感じだろうか。
- Flutter
- 状態管理
- redux
- riverpod
- CI/CD
- Github Actions
- codemagic
- 状態管理
Firebase
- Firestore
- Functions (+ node.js with Typescript)
- Auth
- Dynamic Links
作ったアプリの話(4つぐらい)
ギョームのプロジェクトで感じた課題や実践していること
これ以外にもRailsやVue, React, terraform, aws lambdaなどなど触ったけど人に何かを与えられるレベルではないので多分書かないと思う。言い訳がましいけど新しい気付きや発見があるというよりは「自分はこうしました!」「迷って調べてとりあえずこれで書いたけど合ってるかなぁ」の類が多くなると思う。学習記録やメモということで気軽に書いていきたい。
まとめ
という感じでこれが最後の更新にならないことを祈りながら雑多に書いていきたい。おしまい!
ブログをVue.jsでつくる(全体設計編)
前段
最近業務でVue.jsを触ることが多くなったので、このブログをVue.jsで作ってみようと思った。
仕様(再)検討
これまでのアーキテクチャ構想
- Firebase + Webpack + Vue,jを予定していた
改めてアーキテクチャを考える
- Webpack + Vue.jsは変わらないので、問題はホスティングと
.mdを持たせるストレージ- (まぁもっと全体的なことを言うのであればブログとしての管理画面とか挑戦しても良いんやけど、第1段階としてそこまで手広げたくない)
ホスティング
ストレージ
- 直接リポジトリに埋め込む→Netlifyでホスティングまで全部できる。ただし直接マークダウンを触ってリポジトリにコミットする必要がある。
- ButterCMSみたいなCMSサービス→これならCMS側でコンテンツの管理をしてアプリケーション側はそれを叩きに行くだけでいいのでいちいちgitをわちゃわちゃしなくても良い。あと多分GAとかその辺りのめんどいのを割と簡単にやってくれるっぽい。良さそう。
改めて全体の構成
- Netlify (デプロイ)
- Webpack + Vuejs (アプリケーション)
- ButterCSM (記事の管理)
- Bulma (CSSフレームワーク。余裕があれば)
- これでいきたい。この構成はVueの公式ドキュメントに例が載ってたから間違ってはなさそう。
- 遅くても11月中には完成させたい。
タスクリスト
JAWS-UG 初心者支部#14「AWS Night school & LT」に行ってきた

どうもお久しぶりです。先日、AWSのユーザーグループである「JAWS-UG」の初心者支部の勉強会に行ってきたので、メモなどを共有したいと思います。外部の勉強会に出るのは初めてだったのでドキドキしました。
行った動機
簡単に言うとインフラ周りの知識を身に着けたくて、そのきっかけ作りみたいなところでしょうか。Webエンジニアとして働きだしてはや2ヶ月と半分。少しずつ仕事にも慣れてきたのですが、業務においてインフラの領域で圧倒的な経験値不足を感じています。自分のAWSアカウントを作ってインスタンスを立ててみたりはするのですが、なんというかまだイメージが掴めなかったり、実際どういうことに役に立つかあんまり分かってなかったりします。今回はLTも沢山ということだったので、とりあえず行ったらなんか得るものあるやろ!ぐらいのテンションです。
では以下メモです。
19:05-19:35 AWS Night school 第二回:RDSとS3 (計3回連載予定) AWSJ 亀田さん
S3
オンラインのオブジェクトストレージ。
- デメリット
- OSからマウントできない×
- メリット
- EBSと比べると1/10の費用でデータを保存できる=>補って有り余るメリット。*SLA?
- データ確保領域の設計が不要
- めっちゃ安全(eleven nine)
- その他特徴
RDS
DBのマネージドサービス。
- メリット
- マネージドなのでバックアップとかパッチを当てなくていいので開発だけに集中できるのでハッピー
- 自動でバックアップを取ってくれる上にある程度のバックアップデータ分は課金されない
- 手動でスナップショットも取れる。(S3に入れる)
- デメリット
その他特徴
EC2との違い:スケーラビリティ
- Aurora
- めっちゃはええ
- キャッシュとログをプロセスから分離している
- クローンってなんだ…
- めっちゃはええ
19:40-19:45 LT1:AlexaスキルでDynamoDBを使った minamo173さん
AlexaスキルとDynamoDB
- 会話後にデータを保存/参照する
なぜDynamoDB?
lambdaと相性が良い
- 通常のRDSであればコネクション数が増えすぎて死ぬ
- Dynamoは勝手にスケールアウトしてくれるのでハッピー
データが簡単
- 設定できるキーが多くない
19:45-19:50 LT2:IAM PolicyやRoleあたりの使い方の話 woshidanさん
IAMロールの使用とそれに必要なポリシー
ルートアカウント
- なんでもできちゃう
- IAMユーザーを作って権限(IAMポリシー)をアタッチすればいろいろとできる
- 一時的にな権限の負荷にはIAM Roleを引き受ける(コレ自体もIAMポリシーをアタッチする)
権限の付与とは具体的には
19:50-19:55 LT3:サーバなしで立てるウェブサイト (S3+CloudFront) Nebutanさん
キーワードとなるAWSサービス
- EC2
- CloudFront
- certificate manager
route53
組み合わせで色々できるよ!
19:55-20:00 LT4:IDaaSを用いた複数AWSアカウントへのログインで良かったこと困ったこと 14kwさん
IAMめんどい → one loginでかいけつ
- 以前は踏み台アカウントでログインしてそこからロールをスイッチしてた
- 問い合わせが多発
- スイッチロール忘れたりする
- 問い合わせが多発
良かった点
- ユーザー数無制限のFreeプランがあった
困った点
- APIが足りない
- バグ踏んだ
20:15-20:20 LT5:怖くないクラウドインフラストラクチャサービス kitakatayamaさん
目的
- AWSがこわい人がこわくなくする
紹介するサービス
コンピューティング
- EC2/EBS
- EBSは内部ストレージ。
- EC2/EBS
ストレージ
ネットワーク
データベース
- RDS
AWS Directory Service
20:20-20:25 LT6:MFA、失くした ts03511さん
*MFAとは 他段階認証
20:25-20:30 LT7:Go言語と事例で学ぶAWS Lambda yukpizさん
lamdbaとは
20:30-20:35 LT8:Lightsail 触ってみよう nagashi_ma_wさん
Light Sailとは
20:35-20:40 LT9:初心者だからこそ使いたいBeanstalkで本番環境 bellks51さん
Elastic Beanstalkとは
- autoscalingとかヘルスチェックを自動でやってくれるプラットフォームサービス。
- ELBとかEC2とかの設定を自分でしなくても良い。
20:40-20:45 LT10:TerraformではじめるInfrastructure as Code yusuke_yasuoさん
IaaS:コードによるインフラ管理
ドキュメント/仕様書がないと、どうやって構築したか分からんくなる→復元できなくてヤバイ
コード化しておけば、インフラがブラックボックス化しない
- インフラエンジニアがいなくても大丈夫!→属人化を防ぐ
- コマンド一発で環境構築できるので安心
IAMユーザーを作ってバイナリをインストールしてパスをインストールするだけ。簡単。
- 自動作成されたオブジェクトを手動でいじるとエラーになるので注意しましょう。
感想
事前に「初心者にあまり優しくない」みたいな声を聞いていたのでビビっていたのですが、割とそんなこともなく、そうなのか〜〜なるほど〜〜〜って感じで聞けました。まだEC2とS3とRDSとVPCぐらいしか触ったことがなかったので、そんな便利なものが!と驚いていました。CloudFrontとかLightSailとかでお手軽ホスティングはブログぐらいだったら全然運用に耐えそうなので移行する時は考えても良いかもなー。そんな感じです。楽しかったです。